
A few months ago I wrote about the Decision Model and Notation standard effort. Since getting involved at that time, I am happy to report a lot of progress, but at the same time there is much further to go.
What is DMN?
Decision Model and Notation promises to be a standard way for business users to define complex decision logic so that other business users (that is non-programmers) can view and understand the logic, while at the same time the logic can be evaluated and used in process automation and other applications.
A decision table is an example of a way of expression such logic that is both visually represented as well as executable. DMN takes decision tables to the next level. It allows you to build a graph (called a DRG) of element, where each element can be a decision table or one of a number of other kinds of basic decision expression blocks. That very high level simplified view of DMN should be sufficient for this discussion.
Pipe Dream?
I have seen a lot of standards specs in my time. Most standards are documents that are drawn up by a group of technologists who have high hopes of solving an important problem. Most standards documents are not worth the paper they are printed on. The ones that don’t make it are quickly forgotten. The difference between the proposed standards that disappear (the pipe dreams) and those that survive has to do with adoption. Anyone can write a spec and propose a standard but only adopted standards matter.
I became convinced early last year that the time was right for something beyond decision tables, and DMN seemed to be drawing the right comments from the right people. However, I was shocked to find that nobody had actually implemented it. A couple of vendors claimed to implement it, but when I pressed further, I found that what they claimed to implement was a tiny fraction, and often that fraction had been done in a incompatible way. In other words, the vendor had something similar to DMN, and they were calling it DMN in order to get a free ride on the band wagon.
Running Code
The problem with a specification that does not have running code is that the English language text is subject to interpretation. Until implemented, the precise meaning of phrases of the spec can not be known. I say: the code is 10 times more detailed than the spec can ever be; until you have the code you can not be sure of the intent of the spec. Once code is written and running, you can compare implementations and sort out the differences.
What is a TCK?
What we need is running code. In the Java community since the 1990s there have been groups that get together to build parts of the implementation, or running technological pieces that help in making the implementations a reality. It is more than a spec. The TCK might include code that is part of the final implementation. Or it might be test cases that could be run. Or anything else beyond the code that helps implementers create a successful implementation.
At the 2016 bpmNEXT conference we decided to form a TCK for DMN. The goal is simple: DMN offers to be a standard way of expressing conditional logic, and we need to assure that that logic runs the same on every implementation. What we need then is simply a set of test cases: a sample DMN diagram, with some context data, and the expected results.
Let’s Collect some DMN Models
The DMN specification defines an XML based file format for a DMN diagram. Using this, you can write out a DMN diagram to a file, and read it back in again. All of the tags necessary are defined, along with specific name spaces. Each tag is clearly associated with an element of the DMN diagram. This part of the spec is quite clear. It really should be just a matter of contacting vendors with existing implementations, and asking them to send some example files.
I was surprised to find that of the 16 vendors who claim DMN compatibility, essentially none of them could read and write the standard format. Without the ability transfer a model from one to the other, there is no easy way to assure that separate implementations actually function the same way. Reading and writing a standard file format is relegated in the spec to a level 3 compatibility requirement. The committee does not provide DMN file examples aimed at assuring that import/export works consistently across implementations.
Trisotech was building a modeling tool that imported and exported the format, but they hope to leverage other implementations to evaluate the rules. Bruce Silver in his research for his book on DMN had implemented his own evaluation engine to read and execute the format. There was a challenge in May to encourage support of the format. Open Rules, Comunda, and One Decision demonstrated or released converters. Red Hat was committed to creating a DMN evaluation engine based directly on the standard file format and execution semantics. It is all hampered because Level 1 compliance allows vendors to claim compatibility with virtually no assurance that the users efforts will be transferable elsewhere.
There is, however, a deep commitment in the DMN community to make the standard work. From Bruce’s and Red Hat’s implementations we were able to assemble a set of test decision models with good coverage of the full DMN standard.
The Rest of the Test Case
The other thing we need is technically outside of the standard, and that is a way to define a set of input data and expected results. The DMN standard defines the names and types of data values that must be supplied to the model, but it is expected that each execution environment will get those values either from a running process or another kind of application data store, and where the data comes from is outside the scope of the DMN standard.
We decided to define a simple transparent XML file structure. The file contains a set of ‘tests’. Each test contains a set of input data which is named according to the requirement of the DMN model being tested. Each test also has a set of data values which are the expected outputs of the execution. We even defined how to compare the floating point numbers, and to what precision a matching value must match.
Testing to see if your implementation is correct becomes a very simple task. Regardless of the technology used to implement the DMN standard, one needs code that can read the test values from the input file, given them to the DMN model execution, take the results, and compare to expected results. IF they match, you pass the test. IT does not matter whether your implementation is in Java, C++, XSLT, C#, Microsoft BASIC, Perl, or whatever. Any language can read the test input values and compare the output to the expected results.
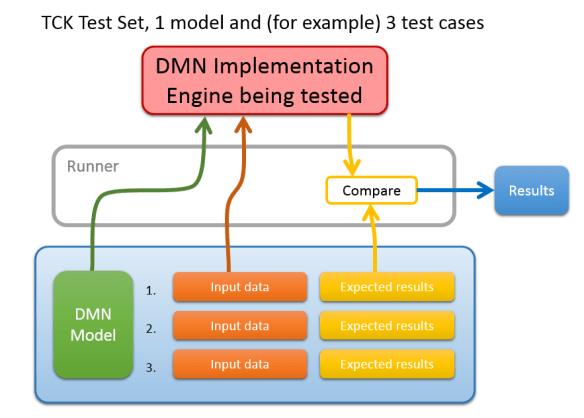
A “runner” is needed to load the test into the engine, and to evaluate the results. Most vendors will need to imlement their own runner according to their own technical needs. The TCK only defines file formats to be read for the test. The TCK does make a Java-based runner available also open source, but it is not necessary that any given implementation use that runner.
Results
The status is today that we have:
- A set of tests ready today
- All available as open source
- Tests touch upon a broad range of DMN requirements.
- Each test is defined according to a specific capability mentioned in the DMN document.
- Each test has a DMN model is expressed in file format defined by the standard.
- Test input and expected values are in a file format that is simple to read.
- Every test has been executed in two completely independent implementations of DMN: one written in Java, and the other written in XSLT.
- The entire test suite is completely transparent: each file can be examined and reviewed by any member of the public by accessing them at the DMN-TCK GitHub site.
Over time we will improve these tests, and develop many more tests, to increase the coverage of DMN capability. We hope to get contributions from more vendors who want to see DMN succeed. Yet we already have a good, useful test set today.
If you are a consumer of decision logic, and you are thinking of purchasing and implementation of DMN, and you don’t want to be locked into a vendor specific not-quite-standard implementation, you should ask your vendor whether they can run these tests. Or better yet, you can try running them yourself. You simply can’t have a serious implementation of DMN, without demonstrating that the implementation can run these fairly straightforward DMN TCK tests. If the tests don’t run, ask your vendor why. Do you feel comfortable with the answer?
Conclusion
The success of DMN depends upon getting implementation that run the same way. Talking about DMN will never assure they run the same way. Advertisements and brochures do not assure that you investment in a DMN model will be usable anywhere else. The only way to assure this is to have a common core of tests and that can quickly and easily demonstrate that they work and get the same results. That is what you want in any decision logic: the same results for the same inputs every time. Ask your vendor if they can run the DMN-TCK tests.
Acknowledgements
No effort like this succeeds without a lot of dedication and long hours by key team members. Eight people have contributed to this TCK, but I want to especially highlight two in particular. Edson Tirelli is technical lead for the Red Hat DMN project was tireless in his thorough examination of the specification and implementation in Java. Bruce Silver has also been a monumental motivation for the TCK, and made a separate implementation in XSLT. By working through all the differences of these two implementations, and coming to a common understanding of all the points of the spec, gives us all confidence that the existing tests are robust and accurate.

Pingback: DMN Technology Compatibility Kit (TCK) |
Pingback: How do you want that Standard? | Thinking Matters
Pingback: Update on DMN TCK | Thinking Matters
Pingback: Strange Feelings about DMN FEEL |
Pingback: DMN TCK – Three Years Later | Thinking Matters