
Attending bpmNEXT conference this week. It was here, two years ago, that we decided to start the DMN TCK effort. How far have we come?
The original idea was to simply to back up the written spec with some real running code. The specification can’t possibly express the full detail necessary for an actual implementation. Anyone faced with implementing DMN would have to make thousands of small design decisions between, say, behavior X or behavior Y. Most of those are arbitrary in the sense that the a user could use behavior of either of X or Y, but what matters is that the product is consistent. Moving from product to product requires that all implementations make the same choices at those levels. The specification is, by its nature, ambiguous on these many small points.
After the first couple of months we abandoned the idea of creating a reference implementation, and pivoted successfully to the idea of providing a framework for publishing test cases which any successful implementation could use to verify and validate their execution. The tests would be files constructed in XML: the DMN model in the standard format, and the test data in another XML which we designed containing input values to submit to the decision model, and output values to compare the output to. To use the tests one needs to write a small “runner” which is code that reads the files, and runs the test.

All of the DMN examples and all the test files are available on GitHub and usable for free with a Creative Commons license.
An Example Test
Here is the XML representation of a simple DMN decision

This decision simply calculates the yearly amount by multiplying the monthly amount by 12. This tests the ability for an engine to parse that FEEL expression, and correctly evaluate it. And here is the XML test file:
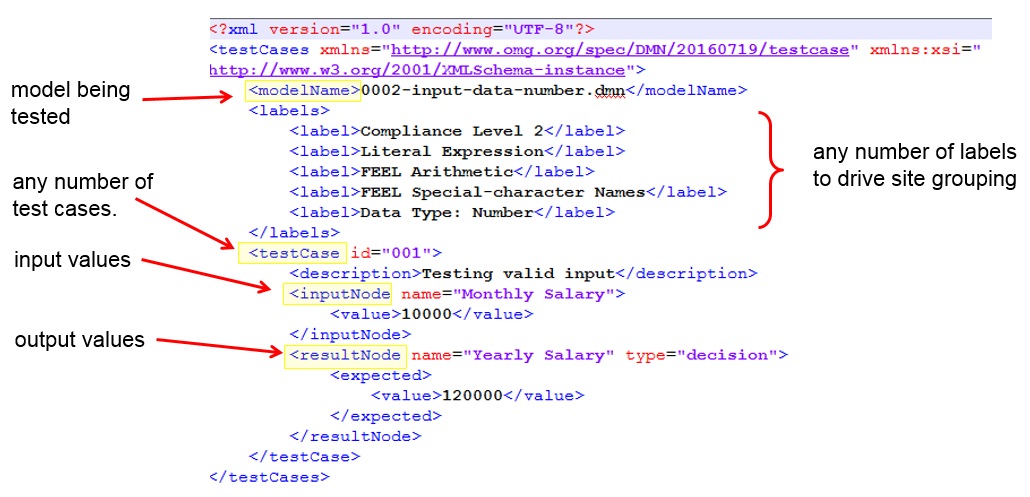
As you can see, it puts 10,000 as the monthly amount, and specifies 120,000 as the yearly result to compare to. DMN models can be much more complex than this, yet the test files generally remain simple lists of inputs and outputs. It really is that easy to create tests, and that might drive widespread adoption.
The results for all vendors are collected and listed in this DMN TCK Results Site.
Collecting Tests
Once the basic pieces were in place, we started collecting tests. The first few tests were models that Bruce Silver had developed for his book DMN Method and Style. The next set of tests came from Red Hat during the testing and finalization of their FEEL evaluator. Camunda added a number of tests. In July of 2017 Actico entered the group, and converted hundreds of their internal tests into the standard form that could be used by everyone bringing the total number of tests to 588.

We welcome more tests. Now that the framework is complete and functional, it is easy to add a DMN model, and a set of input / output values, and that constitutes a new test that anyone can run. Anyone can contribute who can make a GitHub style pull request. The team members will review the test, and assure that it runs on at least one existing engine, and then include it in the official set.
Improving the DMN Specification
While it is not the goal for TCK members to discuss modifications to the DMN spec itself, it is necessary to discuss how to implement parts of the DMN spec, and on many occasions we have run into parts that had been interpreted differently by different vendors, or even parts which were impossible to implement. In many cases the disagreement could be resolved by a careful re-reading of the spec. In some cases the spec was ambiguous, and so a proposed clarification was submitted to the RTF group maintaining the spec.
- Spec did not allow a time duration to be divided by another time duration
- Spec did not allow a date and time type to be parsed from a string
- Spec considered that a list with a single element was in all cases exactly the same as that element alone. When we got into testing, we found that causes any number of paradoxes in the parsing of formulas.
For each of these, and many more, we raised an issue with the RTF to get the spec changed or clarified.
Support
The current effort has received a lot of support from these organizations:

There are seven vendors that have run the tests and contributed results to the results site. However, the DM Community lists 18 vendors who claim DMN support. Why are these lists different? Why have so many vendors not run the tests? What assurance do you, as a consumer, have that those vendors actually run DMN? These are questions to ask those vendors directly.
What is Left to Do?
We are waiting for DMN 1.2 to be released so that we can then add some tests that are not compatible with 1.1, and we expect they will be supported by the new release. When that happens we will create a number of tests around 1.2.
We have not really explored error cases beyond one or two. Clearly there are many more error cases to check for. We might also test DMN models with invalid FEEL expressions to make sure that engines react consistently to those.
The main focus, however, will be adding real-world DMN models which have been developed for actual operating business applications. Those models test not only the execution of the engine in cases that are realistic, but also the suitability of DMN in general to real world problems.

Pingback: DMN TCK – Three Years Later | Thinking Matters