
Big data is a style of data analysis that reflects a return to large, centralized data repositories. Processing power and memory are getting cheaper, while the bandwidth among all the smart devices remains a barrier to getting all the data together in one place for analysis. The trend is for putting the anaytics into the swarm of devices known as the Internet of Things (IoT)
This is an excerpt from the chapter “Mining the Swarm” by Keith D Swenson, Sumeet Batra, Yasumasa Oshiro all from Fujitsu America published in the new book “BPM Everywhere.”
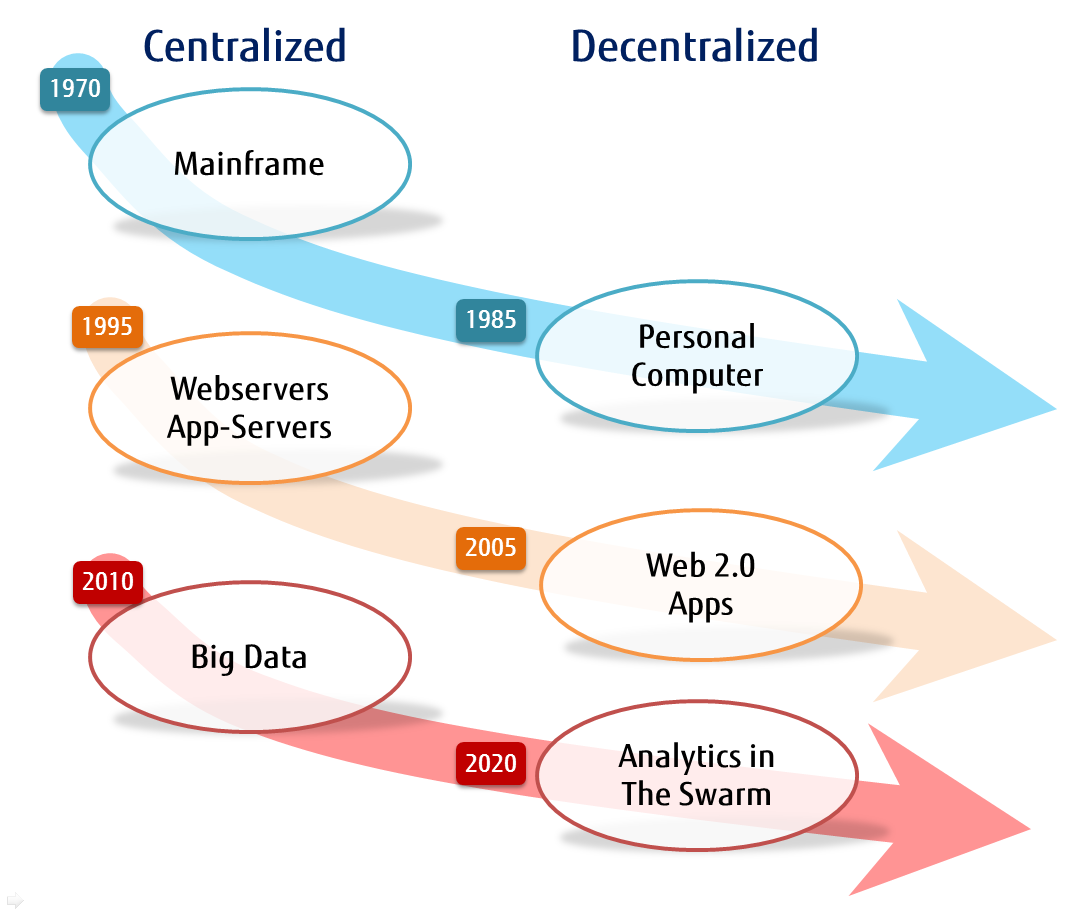
Mainframe Origins
The first advances into the field of computing machinery were big, clumsy, error prone electrical and mechanical devices that were not only large physically but extremely expensive requiring specially designed rooms and teams of attendants to keep them running. The huge up-front investment necessary meant that the machines were reserved exclusively for the most important most expensive and most valuable problems.
We all know the story Moore’s Law and how the cost of such machines dropped dramatically year after year. At first the cost savings meant only that such machines could be dramatically more powerful and could handle many programs running at the same time. Time of the machines was split into slices that could be used by different people at different times. The swapping of machine time to different accounts did represent at the end an overhead and a barrier to use. The groups running the machines needed to charge by the CPU cycle to pay for the machine. While there were times that the machine was under-utilized, it was never possible to really say that there were `free’ cycles available to give away. The cost-recovery motive can’t allow that.
Emergence of Personal Computers
The PC revolution was not simply a logical step due to decreased costs of compute machinery, but rather a different paradigm. By owning a small computer, the CPU cycles were there to be used or not used as pleased. CPU cycles were literally free after the modest capital cost of the PC had been paid. This liberated people to use the machines more freely, and opened the way to many classes of applications that would have been hard to justify economically on a time-share system. The electronic spreadsheet was born on the PC because spending expensive CPU power just to update the display for the user could not be justified. The mainframe approach would be print all the numbers onto paper, have the analyst mark up the paper, get it as right as possible, and then have someone input the changes once. The spreadsheet application allowed a user to experiment with numbers; play with the relationships between quantities; try out different potential plans; and to see which of many possible approaches looked better.
The pendulum had swung from centralized systems to decentralized systems; new applications allow CPU cycles to be used in new innovative ways, but PC users were still isolated. Networking was still in its infancy, but in the 90’s that changed everything.
World Wide Web
The Internet meant that PCs were no longer simply equipment for computation, but became communications devices. New applications arrived for delivering content to users. The browser was invented to bring resources from those remote computers and assemble them into a coherent display on user demand. Early browsers were primitive, and there were many disagreements on what capabilities a browser should have to make the presentation of information useful to the user. The focus at that time was on the web server which had access to information in a raw form, and would format the information for display in a browser. Simply viewing the raw data is not that interesting, but actually processing that data in ways customized by the user was the powerful value-add that the web server could provide. Servers had plug-ins, and the Java and JavaScript languages were invented to make it easier to code these capabilities and put them on a server.
The pendulum had swung back to the mainframe model of centralized computing. The web server, along with its big brother the application server, were the most important processing platforms at that time. The web browser allowed you to connect to the results of any one of thousands of such web servers, but each web server was the source of a single kind of data.
Apps, HTML5, and client computing
Web 2.0 was the name of a trend for the web to change from a one way flow of information, to a two-way, collaborative flow of information that allowed users to be more involved in the flow of information. At the same time, and interesting technological change brought about the advent of `apps’ — small programs that could be downloaded, installed, and run more or less automatically. This trend was launched on smart phones and branched out from there. HTML5 promises to bring the same capability to every browser. Once again the pendulum had swung in the direction of decentralization; servers provide data in a more raw form and apps format the display on a device much closer to the user.
Cloud Computing & Big Data
More recently the current buzz terms are cloud computing and big data. Moving beyond the basic providing of first-order data, large computing platforms are collecting large amounts of data about people as they use the web platforms. The capabilities for memory have grown so quickly, and the cost dropped so quickly, that there is no longer any need to throw anything away. The huge piles of data collected can then be mined, and surprising new insights gained.
Cell phones automatically report their position and velocity to the phone company. For cell phones moving quickly — or not so quickly — on a freeway, this is important information about traffic conditions. Google collects this information, determines where the traffic is running slow and where it is running fast, and the display the result on maps using colors to indicate good or bad traffic problems. The cell phone was never designed as a traffic monitor. It is an insightful engineer to realize that out of a large collection of information for one purpose, good information about other things could be concluded.
Big data means just that: Data that is collected in such quantity that special machines are needed for processing it. A better way to think of it is that the data collection is so large, that even at the fastest transfer speeds; it would take days or months to move it to another location. The idea that you have a special machine for analyzing data does not help at all if the data set needs to be transported to that machine, and the time for this transfer would be prohibitive. Instead of bringing the data to the analysis machine, you have to send the analysis to the machine holding the data. The pendulum had once again swung to centralized machines with large collections of data.
Analytics in the Swarm
The theme of this chapter is to then anticipate the next pendulum swing: Big data style analytics will become available in a distributed fashion away from the centralized stockpiles of information. While the challenge in Big Data is variety and velocity, what sensor technology or IoT brings is the variety of the data which had been previously leverages is what we call “dark data.” Dark data is attracting people as new datasource for mining. Each hardware sensor collects specific data such as video, sounds (in stream), social media texts, stocks, weather, temperature, location, vital data. Analysis of this data is a challenge since these devices are so distributed and relatively difficult to aggregate in the traditional ways. So key analyzing those sensor data is how you extract useful data (meta data) or compress it, and how to interact with other devices or center server. Some say that a machine-to-machine (M2M) approach is called for.
There are a number of reasons to anticipate these trends, as well as evidence that this is beginning to happen today.
Read the rest in “BPM Everywhere” where there is more evidence for how memory and processor performance is fall far faster than telecommunications cost, meaning that processing should move closer to devices. Then examples of how analytics might be used to achieve greater operating efficiencies everywhere.


Pingback: Analytics in the Swarm | bpm and adaptive case ...