
The BPMN specification includes a sample process to use as an example of how you would use BPMN to draw the process and how it would then be converted to BPEL. Bruce Silver has suggested that this be used as an example process to test interoperability between different process diagramming tools. One point in favor of this is that it is fairly well fleshed out and documented. Also, it is a real process that would be reasonable to use in real life.
As I set out to implement this process, it struck me how dramatically different the process would be drawn if you had an implementation engine that supported human activities directly. Many of the things which are broken out into seprate activities would be combined into a single activity. Even at the basic level, the model would be different, because you would be modeling the human activities, instead of the flow of data back and forth. The process as it is diagrammed was designed from the beginning with the idea of being implemented on a BPEL engine. The process model as it is drawn approached everything from the point of view of what would be possible with a BPEL engine.
The best way to explain this is to show what the process would look like if you were to implement it using a human facilitation style BPM engine, and that is what I will do below by applying the Methodology for Human Processes to the email voting scenario.
The first step is get a list of the actual human activities that appear in the process. To do this we fly up to the 40,000 foot level and look down, ignoring as much as possible the details that came into the process due to the orientation to be able to executed on BPEL. We start with the activities that have to be done by people, because they require human intelligence, and really can not be automated.
1. Choose the issues for this week. The scenario assumes that there is an open ended list of possible issues which are being continually added to. It is not possible to talk about all issues every week, so someone must pick the most important issues. It is not possible to automate the determination of what the most “important” issues are, so this task of picking 1 to 5 issues for discussion and voting this week must be done by a person. There may not be enough issues this week, or it may be a holiday week, or any number of other possible reasons not to discuss issues this week, so the issue manager must choose whether there are “Issues” or “No Issues” this week.
2. Discuss Issues. There is a period time within which people are allowed to discuss the issue, and that means having access to the issue descriptions, access to comments that others have made, and the ability to make comments on the issues. This is performed simultaneously by a large number of committee members.
3. Determine is Discussion is Over. The issue list manager is asked in this process to take a look at the results of the current discussion, and decide whether the discussion needs to continue or not. Since this is a decision that is not automatable, we have to have the issue manager do it. There are two choices: “Continue the Discussion” or “Finish the Discussion”.
4. Vote on the Resolutions to the Issues. Mainly just recording the results of the activity. In this step, we can make use of a parallel activity called a “Voting Node” to allow everyone to be informed about the vote, to collect their responses in a convenient way.
5. Remedy Voting. This is a human activity in the case that voting “fails”. Voting can fail when not enough people vote. The original BPEL oriented process had a number of steps, most automated, to handle this situation. When considering the human tasks, an analysis of the process leads to the conclusion that a large number of the possible paths are automated, but a few of the paths require a person to address the situation by either reducing the number of voters or reducing the number of options being voted on. The key here is that in those situations that a human must be brought in, what is important is that the person be notified that the voting has not worked, and be given a couple of options to remedy the situation. So for the purpose of modeling the human process and for making the decision of how to proceed, I have collapsed this to a single activity node for a person to perform. The automated aspects are ignored at this point.
Then we have human activities that are necessary because the technology is somewhat limited, and not completely automated, and so there are some tasks which people do manage and maintain the systems
6. Moderate the online discussion. Unfortunately, the discussion is not completely self moderating, and so someone must have special access to possibly delete spam and inappropriate messages, and to help people to keep the discussions going.
7. Hold or attend conference call. The discussion on the issues is not completely on-line discussion, but also conference calls are a way that people come to a common understanding of the issues and resolutions. Someone needs to set for the conference call and moderate while it is happening.
The above seven activities account for everything that is done by people in the process (if I considered everything correctly). There are only two roles in this process. The Issue Mgr is the person who is managing the issue process. This could be multiple people, but only one of them would act at a time. The other role is the Committee which is everyone who is involved in discussing and voting on issues. The committee members are responsible for Discussing Issues and Voting, while the Issue Mgr is responsible for all other activities in the process.
The email voting process actually consists of two processes: a singleton starter process which loops and starts an instance of the actual issue voting process every week. The issue voting process then has two subprocesses. Because we have only seven human activities, I decided to keep it simpler and not use the subprocesses, and to do everything in the two main processes, though this would have been a choice if you wanted to you could use subprocesses to group things differently.
In doing the analysis I became aware of a strange behavior of the original process as written. You could very easily be in the position of being asked to run multiple conference calls at the same time. Remember that issue handling process is started every week, which drops into a subprocess for decision handling and another for voting. Each of those subprocesses have logic for determining if there will be a conference call during that time period, and to trigger an activity for handling the conference call. The discussion subprocess may loop, potentially for multiple weeks. It is possible that you will have multiple instances running at a time, and if this is the case, each instance will prompt for a conference call. The issue manager might manually avoid having multiple instances running at the same time, by deciding not to discuss anything in the new process instance as it is started, but this rather begs the whole question of why there are the possibility of multiple issue resolutions processes in the first place; why not simply have the singleton starter process do all the work? Finally I settled on the idea that issues are grouped, and it makes sense to have the possibility of multiple issue groups being discussed and/or voted at the same time. The conference call on the other hand is scheduled every Thursday, and takes place regardless of the number of issue groups currently, and therefor should be associated with the singleton starter process, and not the instances of the issue voting process.
The starter process

There is a single instance of this process, which loops every week. There are timer delay nodes that cause things to happen at specified times. At 9am Monday morning, an instance of the issue list process is started. This is done with an “asynchronous” subprocess node; this is a node that starts a subprocess, but continues without waiting for that process to finish. The ability to start a subprocess and not wait for it is commonly available on human process engines, and is a standard part of the XPDL file format. This is one clear area where the capabilities of the engine will certainly effect how you draw the process. If you think about it, the purpose of this starter process is to create instances every week of the email voting process, but because in BPEL there is no operation for expressing this, the original process would “send the issue list” and the “receipt of the issue list” would cause the creation of the process. This is quite strange when you consider that the issue list itself is probably on a server that is already accessible by everyone, and does not need actually to be “sent” anywhere! The sending and receiving of the issue list is an artifact created just to get around the problem that BPEL does not have an operation to create a subprocess! This is also partially because BPEL is not modeling the work that people do, but only modeling the sending and receiving of data. OF course, it is possible to model the whole world in terms of sending and receiving bytes, but it is far clearer and easier to read a process diagram with a node that creates the subprocess directly.
Then, on Thursday at 9am there is an activity to hold a conference call. This is assigned to the Issue Manager. I embellished the process a little bit to also give that manager a choice of whether to conclude the working group or not. The original process had a branch node that checked something to see if working group was still active, but then someone would have had to have taken some action somewhere to indicate that the working group is completed. Drawing it this way ties both the human indication that the working group is finished together with the completion of the process. Every week, the conference call task will be concluded with the choice “Continue Working Group” which is no additional effort over simply saying that the conference call is done. But, when the time comes that the working group is no longer active, and there is no need to ever have another conference call or another issue vote, then simply choosing “Conclude Working Group” provides an easy to complete the process without using the administrator’s console.
The Issue Email Voting Process
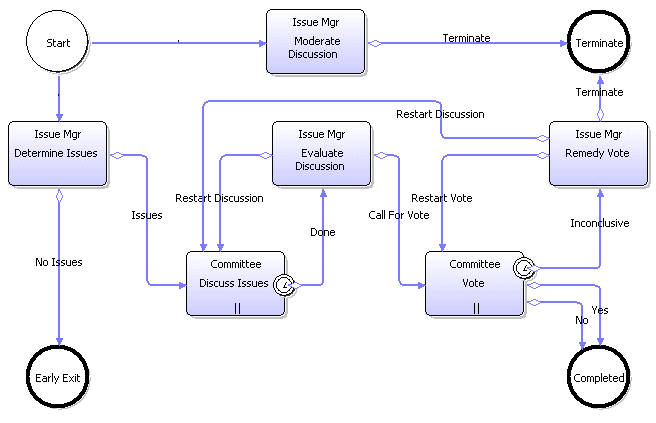
This process starts two activities from the start. “Moderate Discussion” is designed to remain active the entire time the process is running. Most of the time the process will be in the Discuss Issues step or the Vote step, and so really this step allows a place where the issue manager can moderate both discussion and voting. I embellished it a little bit to add a “Terminate” option that would shut down the process before discussion or voting was finished.
The main process is the lower 5 activites. First the issue manager decides the issues to be discussed. Second, the issues are discussed by the committee. Then the issue manager decides if the issues have been discussed enough and completes that by either “Restart Discussion” or “Call for Vote”. If it is the latter, the committee is asked to vote. If the vote is not conclusive, then issue manager must Remedy Vote and where he will be able to reduce the number of voters or the number of resolutions to vote on, and to choose either to Terminate the process, go back to Discussion, or go back to Vote.
How does the “Vote” work? Here we cheat a little bit by using a capability of the engine that present the vote options to a number of people simultaneously. It gives the options of “Yes”, and “No” to all committee members. People choose one, and the process engine tallys the results. On the outbound arrows, you can specify how many votes, or what percentage of the votes, are necessary to consider the an option successful or not. As soon as the success criteria is met, the voting activity is concluded. There is also a built in timeout so that if a vote is not concluded in a period of time, then the activity can be concluded down a third arrow which leads to the Remedy Vote activity. I know this seems like cheating to pull something like this out of the hat, but I did not make up this process, voting steps are relatively common in the worplace, this is a real node type available in a number of human process engines. As much as anything else, this should make it obvious that the way you draw a process in BPMN is highly dependent upon the underlying technology that you are going to use to implement it. For the discussion node we also use a voting node, even though we are not voting, and again it ends with the built-in timeout mechanism.
How are people notified about what to discuss? How are they told what to vote on? When you assign a human level activity to a person or group of people, that activity automatically includes a notification mechanism that tells them what they are to do, and includes information about the specific case. Simply assigning the “Discussion” node to the Committee means that everyone in the committee is automatically told what it is they are to discuss at the time that the discussion is to start. Simply assigning the vote node to the Committe means that they will be notified what the voting options are at the time they are to vote, and their votes are automatically collected and tallied.
What about the nodes to send reminders? Again, this does not need to be explicitly modeled because every human activity automatically includes (a) notification, (b) information, (c) conclusion, (d) deadline, and (e) reminders. We just set up the discussion activity to have a reminder after 6 days. Similarly on the voting node, we have a reminder after 6 days. That reminder on the voting node can be considered a “warning” since if the vote has been concluded, then the reminder will not be set. The BPEL oriented process had to stop the voting, and then go back and restart the voting after the warning, but that is not necessary when the voting node can send reminders without stopping. Even the nodes for the issue manager can have warnings and reminders if the issue manager goes for a time without taking care of the task.
What is this Human Process good for? By showing the process, you see what everyone is expected to do. At each step in the process, a person is told that something must be accomplished, and given a set of choices. The diagram is oriented around what it is that people do, not what bytes are sent and receive. As such it is useful for explaining what will happen next in the process depending upon which choices are made. This is useful for training people, and it is useful to display the current running status of the process instance to people. But some will point out that it is not complete; it does not contain a representation of all the automated actions. This is true, but no process map is entirely complete. For example, the process variables are not displayed in either the BPEL oriented process, or the human oriented diagram.
What Does All This Mean?
The key point I am trying to make is:
above is a specific process modeled in BPMN, but the way that you model in BPMN depends upon the methodology you use, and the underlying technology that will support the process
There was a desire for BPMN to represent the Universal Lingua Franca of business processes. If you want a particular process, then just draw the diagram in the one true univeral BPMN way, and you will will be able to run that on any engine. But that only works if the engine you are using matches the capabilities you had in mind when you designed the process. A BPEL engine, for example, allows you to send and receive data, and so your model is always around sending and receiving of data, which is useful if that is what you want to do. But many people want to model what humans do in an organization, and modeling humans as sending and receiving data is quite uncomfortable.
BPMN is a great notation standard. Still, implicit in that BPMN diagram is a set of assumptions about the underlying engine that the process will run on. Perhaps more importantly, the diagram is designed to communicate a particular thing to a particular audience. If you want to communicate to people, you will draw the diagram one way, if youwant to communicate to software developers, you may find the need to draw the diagram a different way. BPMN was designed to be used in both these domains, and still offers a great service that at least we have a set of symbol which if used consistently will be readable by everyone.

Hi Keith,
Happy New Year! Very nice post around the needs of human and group activities.
There are a couple of way BPEL engines can support this use case:
#1) have support for a special/proprietary human activity – BPEL is fundamentally designed around a set of activities so adding a new kind of activity breaks portability but not the overall design of the language.
#2) create a work manager service, declaratively/rule driven – who are the assignees, what are the notifications, what are the voting rules, what happens when a task expires, etc… and have a BPEL scope macro for enacting and listening to notifications from that task service.
There are a few benefits to approach number 2: there is a first class concept for modeling user activities and the definition of the activity is completely encapsulated from the client enacting the task and listening to notifications. Over time, the implementation of the task can change (a lot of the use cases I have seen in the last few years end up being better captured by a rule engine (vs. a state diagram). And finally the work manager service can be enacted by both process engines and UI page flows so there is a higher degree of reuse.
What I feel is missing is not as much the standard for capturing how the activity manager is configured but the interface that all human activity managers should implement. The equivalent of rest for human activities. What happened to ASAP?
Something like ASAP and a first class activity in BPEL to interact with ASAP services would I think have a much more profound impact on distributing business processes across the web than fighting on visual modeling and portability of business processes.
This is at least my perspective as an outsider.
Cheers and again Happy 2008
Pingback: links for 2008-01-06 « steinarcarlsen
Really needed to say I’m ecstatic I came upon your webpage!