
Looking at the spectrum of different process technologies, we can identify seven distinct categories, and we can organize them according to how predictable the problem is that they address.
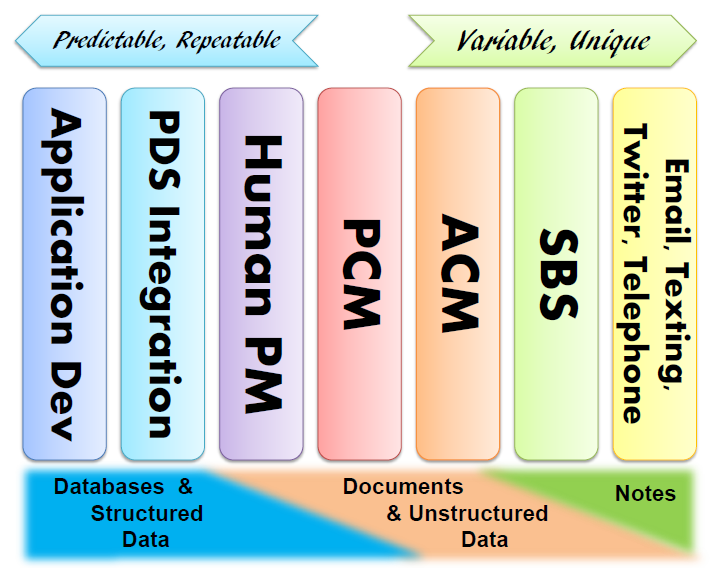
I have been kicking around this chart of 7 types of process technology for a few months. In Portugal in April I presented an expanded explanation of the categories, which got a number of positive comments.
That video is somewhat trimmed and cut and skips some of the categories. Here is a more complete presentation of the domain concepts:
Rough Transcription:
This presentation is to help clarify the spectrum of approaches that are available for supporting business process-like activity. Others have attempted this, but my approach is based on comparing the amount of predictability of the particular business problem being solved. Using predictability, we can identify seven different technological approaches that are in regularly in use today, and picking the right one is important.
Lets start with the overview and big picture. The setting is that we want to produce a system to support people doing work. Since the beginning of the information revolution, you have always had two extreme possibilities: application development and no development.
On the left of this diagram is application development. This refers to traditional programming techniques: you hire a programmer, or a development team, maybe a system architect and a user interface designers. What results is a custom application designed for a specific purpose. Such an application can still support a business process; the process is coded into the program logic directly, and changing the process requires reprogramming the application.
On the right you have the “no development” option. One worker can send an email to another worker asking for help, or delivering a result. Texting, instant message, and telephone calls fall into the same category. There is no pre-programmed coordination of activity, there is nothing in the system at all about a process. It is entirely manual in the sense that each action has to be a deliberate decision by the people involved in the interaction. A person decides to contact another person when they wish, and however they wish.
On the left, the traditional application development paradigm allows for the most powerful support for coordination, almost any interaction pattern can be scripted, enforced, monitored. but it is expensive to develop, and expensive to update when your business changes.
On the right there is no programming of the coordination, and so beyond the initial infrastructure, it costs nothing to prepare a new business process. But it puts the burden of knowing and following a process completely on the users. They must be more aware of the process, possibly trained, and there will be many mistakes, retries, and patching up done while working.
Predictability of the process determines how much return you are likely to get on an investment. A very predictable, repeatable process will produce a high return on investment. Consider a factory: a company that can define exactly what mechanical actions need to happen in order to make a manufactured process can invest millions or even billions of dollars into a factory, which then turns out products cheaply. A massive investment requires a massive scale in order to pay back the investment. The same is true with the software in a collaboration system. You only make a large investment if there are going to be a large number of cases and/or each case is valuable. The less predictable a process is, the less you want to invest. When the process is very hard to predict, and you need thinking people making decisions on what to do next. Using the basic communications model you save the investment, but there is a larger burden on the workers.
The broad field of process technology fills the gap between these extremes. Business processes constantly need change and improvement. Organizations need some support to make sure that processes are being done consistently, but you can’t always afford the heavy investment in a custom programming job. The goal of process technology is quite simply to offer a way to get support for a process that is less costly to implement and less costly to change. This process technology was originally called “worflow” in the 1990’s, and later BPM in the 2000’s.
What we are seeing now is a spectrum of process support technologies. All of them claim to support flexibility for processes, as well as incremental improvement. But each technological approach has different affordances for supporting flexibility, as well as differing levels of power in being able to control processes. We can organize these technologies into an ordered spectrum according the predictability of the work situation they ideally support. On the left you have the most power to precisely define and control processes, and at the same time the most cost to implement. As you move to the right, it becomes easier (less costly) to implement/change a process, but you power to control the process also decreases. Until you get to the far right where there is no upfront investment and no ability to control the process.
Remember, is is the predictability of the “business problem” that is considered. If the work itself if highly predictable, then you pick a technology to match. If the work is entirely bespoke, then you pick the technology to match. Clearly, the more predictable the work is, the more benefit you will get from proper process support, the further to the left you are willing to go, the more investment you will make and still get a positive return on investment.
At a high level, let me introduce the seven domains. On the left you have traditional programming as discussed. Right of that is process driven server integration, where you use a process diagram to coordinate information being passed between systems when you need to accommodate these systems changing every now and then. Next you have Human process management which takes a strong process orientation, but which adds capabilities to deal with the unpredictability caused by assigning tasks to humans, such as reminders and escalation. Next is Production Case Management, where the process is less fixed, and the user decides at run time what to do next, from a menu of possible actions. The menu is fixed, but it is case management because the user decides what is best at run time. To the right of that is Adaptive Case Management, which is like PCM, except the user can decide to put new actions on the list of possibilities at any time, in order to address problems which were completely unseen at the time. Next comes Social Business Systems which has actually very little support for process, just some basic, predefined interaction patterns, as well as a collaboration model with role oriented access control. Finally, on the far right, the complete and utter lack of predefined process, you throw up you hands and submit to manual email mode. You will notice that the dominant ways information is structured changes as well, as indicated in the bar at the bottom.
Let take a look at each domain of predictability in detail.
1——–
Traditional development is the most powerful. In a 3GL, you can implement literally any process. The process state is held in variables, or database column, and hand coded logic can change this state using any logic or information needed. Any user inteface can be exposed at any time in the process. Programming the process requires a trained programmer, and making any change to the process does as well. This programming can be quite tricky even for an experienced programmer. It is easy to make errors, and so a lot of debugging and testing is required.
When thinking of actual real-world examples of this, I think of factory floors or fast food restaurants. In a burger joint, you know those cash registers that automatically send your order to someone in the back. Or programs for custom machinery to perform a specific manufacturing step. Both of these cases will be run many many times, and the process is more or less completely predictable and under the control of the organization. The high predictability, and the high numbers of cases, can justify a high initial investment to get the process exactly right without any limitations.
2———
The second domain is quite similar to this in that you have completely automated processes, but I call this “Process Driven Server Integration” because it has to do mainly with coordinating the work of many separate systems. Consider the example of a phone company when someone buys a phone. You have to access one system to allocate a phone number, another system to set up an account, another system to order the phone, aother system to arrange for delivery. This is called a “business process” because it is key to getting business done, and it spans many separate systems. The challenge here is first to make sure that all the right updates are being done to all the right systems, and doing this via a process diagram is a big benefit. PDSI systems invariably have some way to model the process, and that is how you distinguish them from traditional programming. This process model helps to structure the code in the way that makes it easier to cope with change. For example, when your system to track user accounts is changed, it is relatively easy to change the code associated with that one step, and be relatively assured that nothing else is broken. If the market changes, as it did when SIM cards were introduced, it is relatively easy to add a step to call a new system for ordering a SIM card, and be relatively assured that the rest of the program remains unaffected. The process model formalizes the communications between systems in such a way that it can be changed.
The PDSI models are dealing with low level data, picking of a record from one place, transforming it, and sending the result to another place. The modeling must be done by a programmer who understands data structures and transforms, although a business person might be able to review the model for conceptual correctness.
Straight-thru-processing fits into this category. In 2003 there was a lot of hype around BPEL (Business Process Execution Language) being the unifying standard for BPM. Actually, BPEL is an excellent example of this category since it offers a process model which sends and receives information to and from web services. BPEL has a concept called a “participant” but that participant must be a web service, which was considered misleading by people working in more human support fields.
Process Driven Server Integration is, at a high level, a form a programming that uses process models to gain additional flexibility to cope with changes in the distributed server. Even so, such changes are usually planned weeks or months in advance.
3———–
Then there is a domain that is slight less predictable than PDSI, and that is Human Process Management (HPM). HEre again you have a process map, but while in PDSI the map is showing actions to send and receive information from servers, in this domain activities are assignes to people. Humans are in many ways less predictable than servers. In PDSI, the process will decide which server to handle a task, send the request and 99.95% of the time it will be done. however, for humans, it is not uncommon for a task to be assigned to one person, then reassigne to another, then forgotten about until a reminder is sent, and then finally complete by someone else who works with the assignee. Human process management has to be designed to support the idea that you can’t state in advance exactly who will do the task. Usually this technology has strong support for roles which is a way of indirecting the assignment to a structure that can be easily changed from day to day, without having to edit the process.
Another aspect is some form of task list so that humans can pick the best things to do at this moment from the rest, as well as deadlines to help indicate that something has been sitting too long, and reminders to actively prompt for something that is late. There is usually an escalation feature that allows a task to automatically reassigned if it takes too long. It is worth noting that none of these features are needed in the PDSI domain: if a server fails to respond, then sending a reminder will have no effect.
A good example is expense report handling: there are a number of people involved who do different tasks like approving. There are reminders if people are slow, and tasks can be reassigned if someone changes position.
Human process management must be much more easily changed in the face of market changes, business changes, or personnel changes. People are changing positions within the organization every day. Often the process will need modification to fit the skill of a particular subunit, since the human skills are not as precisely defined as computer programs. In general, the process modeling has to be at a much higher level, with much less programming involved. That means that you can’t control the process to the same degree as PDSI.
4————
Production Case management is more flexible still. Here, the process itself can not be completely defined in advance, yet we can define a set of possible actions that one might want to do. We can automatically determine what to do, so the user has to decide, based on experience, what the right next thing to do.
A good example is a help desk or customer support center. In this case there are set of possible actions, such as refund the customer, order a replacement, escalate to development, etc. Mostly the customer support agent answers questions, but if warranted, can call one of these steps into play. The agent is a knoweldge worker who learns the specific trouble modes that people are likely to encounter, and learns to determine the right course of future action for each case.
We call it PRODUCTION case management, because it designed for high volume situations. I call this “knowledge workers for hire” as opposed to knowledge workers who own a case as a business. So if you have a 30 person, or 100 person, customer support department, the actions that those users can take will be defined and provided by the development team, and the user will not have any ability to add new actions to the set. Like Human PM there is a separation between the people who determine the possible actions (the developers) and the people who use the actions (the users).
5————
Adaptive Case Management is even less predictable than Production Case Management: you can’t predict the process, and you can’t even predict the actions that you are going to need in advance. Some regular actions are known in advance, there there exist a significant number of cases where a new action will be needed that has never been done before. In some cases this is a unique action, that will never be done again.
An example is a doctor. Much of what a doctor does is routine, but diseases are very complex, and the symptoms are not always clear and unambiguous. There are cases for every doctor every day where either the symptoms are unusual, or there is a new treatment available they have not tried. The doctor might research a bit, discover a new drug that studies show is promising in this particular combination. The doctor needs to be able to at that moment draw up a new treatment plan for this patient. He can’t wait until the end of the month for a programmer to update the software. He can’t even wait until the end of the day in most cases.
To be completely clear, most doctors today use no process support: they simply type a text description somewhat equivalent to an email message. The reason that process support has evaded professional fields like doctors is because so many different processes are needed that can not be known in advance, that any technology to the left of ACM would simply be too costly to use.
ACM offers an approach that is very very easy to create and modify processes, so that individual knowledge worker can modify them for one-off situations. This means that essentually no programming can be used within the process, because any programming in there would be a barrier to allowing the knowledge worker to change it. It seems that what we call a process here starts to look mostly like a simple checklist. Most of the information is in documents or PDF reports, an quick notes.
Going from left to right, ACM is the first domain where workers are asked to sit down and plan what they are going to do to complete a case, and to create a list of goals to accomplish that plan, and that makes ACM different from everything to the left of it.
6————–
There is room for one more domain between ACM and email: this is a domain that has very little or no process customization to it, however there is a greater amount of collaboration and time sequencing than manual email. This domain has people collaborating on permanent artifacts, and often use network connections to control access.
The best examples I have of this category are domain specific cloud applications to support specific collaboration scenarios. For example EventBrite and eVite are cloud services to help you coordinate a meeting or small event. You create an event record, specify the date, and then invite people. A notification is sent, and then those people can indicate whether they are coming or not,and a tally is kept. As it comes close to the event, reminders are sent out (this is the process aspect). And there often is a place to share documents. For example some of these allow you to declare some people as “presenters” (thats a role) and presenters can upload their presentation slides to share.
Content management systems basically fall into this space if they offer some sort of role capability that can be used to control access to sets of documents. Content management systems usually have some form of review or approvals process. However, some systems that call themselves content management may have quite strong process support qualifying them to be called ACM or HPM.
The term “social” is included here because there is an increasing trend to allow these spaces to be self defined and allow people to make use of networks of connections for controlling access. I am not saying that facebook necessarily falls in this category, but rather there are social features that help this kind of basic collaboration be distinct from plain old email.
7——
And that bring us to the domain that supports the most unpredictable, and that is simply email or other direct communications technologies. What really distinguishes this is that you write up something and send it. There are no permanent structures and no collaboration. People can reply, but that is nothing more than a new email.
This domain will never go away. There will always be the need for direct, unconstrained communications, e.g. “I am running late for the meeting” or “Here is an interesting article about some product.” or “Oops I accidentally rejected that PO, can you resubmit it?” There are many many human activities that simple are not repeated enough to make an application specifically for them. These may be used only once.
There are two disadvantages: first of course is that user must manually implement any proper protocol, and that depends upon expensive training. second is that the record of what happened is either missing or much less useful.
Many things are handled in this way, that really should be in the future handled better another domain. If the work is to some degree predictable, then using an option to the left will be an advantage.
————–
Note two things: in all of these I did not use the term BPM. That term is not well defined, and there are people who will vigorously defend that BPM means one or another of these domains, or sometimes all of these domains. My advice is that when someone mentions “BPM” you try to determine which of these technologies they are particularly referring to.
Second, I did not fall into the trap of saying that processes are defined to some level, but when an exception occurs they switch to another category. In any of these categories there will be the need to occasionally send someone email to fix a problem, or handle a case that does not fit perfectly. In each domain, I gave an example of work that was inherently predictable at differing degrees. I did not conflate the idea of predictability and exception handling. There will have to be exception handling, but the normal, non-exceptional work in these domains is inherently predictable to those various degrees.
Summary
(review each category at a high level)
When discussing categories with people, be aware that most vendors will claim to support many or all of these categories with a single product. Be skeptical. In many cases a quality in one domain cancels out a quality in another domain. I am not saying it is impossible to cover multiple domains, indeed the bigger systems accomplish this, but to do so requires that they have a specific MODE for implementing a particular domain. Be very wary of any system that say it has email, and processes can be changed by anyone, so it has unified all of these domains in a single product.
I hope this has given you an idea of the how there are different domains of predictability for which different technological approaches are appropriate. For more information, please check my blog where you will find many more details on these topics and others.

HI Keith, no diagreement that these are the process types we encounter. It covers the spectrum of processes that I described in 2010 and segments them a bit more:
From my perspective these are not different process types or process domains per se because if we define a process to represent a goal achievement or customer outcome then any mix of all seven types of action may be needed to achieve a single goal. How will you do that with mutliple systems?
I also agree that it is important that potential buyers are VERY sceptical in regards to vendor claims. And if it is just because any marketing material or RFI or RFP might describe needs in sufficient detail. But that does not say that it is impossible to have all these features in a single solution. Clearly looking at solutions that do only one thing they might do that better, and if it is only because they do not have to consider the integration aspect or like with Social goal-oriented interaction or security and authorization needs. Buying seven product that each is best in what it does means a substantial implementation effort to make them work together.
Install and try in a proof of concept is the only professional way. As we cover the complete process spectrum we do recommend that prospects install, trial and verify. I see no need to be weary or to claim that different technological approaches are needed to support these process interaction types. There should not be different implementation ‘modes’ but I am not exactly sure what you mean. But yes, a social interaction will not need a flow diagram. And yes, non-technical users should be able to do as much as possible if so desired. Not everything will be available to them. The more the better.
PS: … and by the way …. as most people focused on processes you did not consider that most processes have the need to deal with inound and outbound business content and most systems on the market require additional implementation effort to integrate content functionality (not just storing Word or image blobs). In Papyrus that is an integral capability as it is where we originate from as software product. it is also the main reaosn that flow diagrams aren’t holy to us …
Max, I have a pretty good impression of ISIS Papyrus, and I am inclined to give it a lot of slack, but you are missing the point if you think that it is the one technology to bridge all of these domains.
Consider the first domain, traditional programming. In this domain use of a 3GL eliminates all constraints. There are many kinds of system that are possible that would be impossible with ISIS Papyrus. Just to toss out a few to illustrate the point, in a 3GL you could write a database, a telephone voice-mail box, code to run a Mars rover, or an autonomous quad-copter. There are many things that you simply would never use ISIS Papyrus for, and even discussing the use seems a bit humorous. Toss out real-world constraints like cost and efficiency, and you might conclude for a theoretical point of view that you *could* use ISIS Papyrus for these jobs, but no sane system architect would.
Similarly for the second domain. Imagine VISA and writing software to clear check transactions, the shear volume and criticality means that VISA is going to make a larger investment in order to get the small benefit multiplied millions of times a day. PDSI systems will often compile down to machine code for very high scalability, and they deal directly with data at a very fine grained level, for precise control of how information is handled.
Vendors who claim to support “all categories” are usually stretching the truth, glossing over details, and treating inconvenient use cases as outliers that can be ignored. I don’t have any fear that all Java programming will be replaced by ISIS Papyrus anytime — not ever. Same with category 2 and 3. You have railed publicly against process diagrams, but in these two categories process diagrams are highly desired by the users because of the control. There is a downside to process diagrams in other domains, but NOT in these two domains. Is it possible to do it without process diagram — yes it is, but no sane system architect would do that.
On the other end of the spectrum, I don’t think that Microsoft is afraid that ISIS Papyrus will replace Outlook or Exchange any time soon.
As I mentioned at the top, I am inclined to believe that ISIS Papyrus is a powerful solution in the middle range, but still, consider the difference between PCM and ACM. PCM is programmed by a development team for a particular application. Developers want and need a powerful programming capability, visual or otherwise. Yet ACM is for knowledge workers to configure to their needs. The moment you use a powerful programming language (for PCM use) you invalidate the system for ACM use. You might command “This is an ACM application so don’t anyone use the programming language!” My point about “modes” is that for ACM capability you need to be able to turn off the ability to use that programming language, so that you can assure that it will work like ACM.
In conclusion: I simply don’t buy the idea that ISIS Papyrus is the “one ring to rule them all.”
You are a bit out of date coding 3GL as in 1 – have we not moved on to “6GL”? As for the rest all about support for business logic both human and system which a good 6GL should support? Not got it yet? Who needs BPEL BPMN or old style workflow…..?
The term 3GL is a bit archaic, and by that term I simply mean Java, C#, C++, PHP, Ruby, Python, JavaScript etc. The bulk of all coding is done with these. 4GL products never attained dominance. Some thought we would be programming in pure UML, but that never happened. The other categories can be seen as different directions that a “generation” can take. Particularly PDSI which adds a process diagram (BPMN or other) to the regular job of programming. As we move more to the right, the supporting platform looks more like a spreadsheet, and less like 3GL. What “generation” is Excel? That question is not really meaningful. I have struggled with how one might unify these approaches with a single 6GL-like concept, but I don’t see that happening, at least not in foreseeable future.
Well I have news for you that door has opened! The biggest challenge is people do not believe or want to believe…..it is quite disruptive as you might imagine. Interestingly our CTO who managed a big re-write in the late 90s was ex ICL; sadly no longer “with us”. He recognised immediately what had been created as ICL had tried and failed having spent some £20m! Being a decade plus ahead of time has not been easy but now the move to people and process at enterprise level is taking place – your 7 types of process technology are needed to make it work; a very useful summary. It is just the start of a new journey for business software. So are up for a challenge…..? Get in touch! Easily found on twitter…..
Your views are comprehensive and detailed. However this brief summarise in a business context a philosophy that Procession has at core to all its development. I believe the Seven Domains that recognise the very structured to the unstructured could be summarised as follow;
1. Traditional development and hand coded logic using such logic or information needed. This requires a trained programmer
2. This addresses what Keith calls “Process Driven Server Integration” with the core focus on coordinating the work of many separate systems. This requires programmers who also understands data structures
3. Process Management (HPM) about actions to send and receive information from servers that are assigned to people with strong support for roles and assignment of work with escalation and deadline capabilities
4. Production Case management where work may not be completely defined in advance but can have a set of possible actions, so the user can to decide, based on experience, what the right next thing to do.
5. Adaptive Case Management is an approach required to be very easy to create and modify processes based on customer centric requirements. Individual knowledge worker can modify them for one-off situations. This means that essentially no programming but allowing users to define how to achieve the required goals.
6. Social Business Systems a domain that has very little or no process customization to it, however there is a greater amount of collaboration and time sequencing and have some form of review or approvals process requiring role oriented access control
7. Other direct communications technologies such as email. There will always be the need for direct, unconstrained communications
As such there are these different domains of predictability from very formal to the informal which under the components that have evolved over decades require different technological approaches. This is where Procession challenges this disjointed technology approach with a step change that addresses all these essentials in one tool all built or recognised as required via a graphical model that allows transparency and understanding by all.
Procession’s core design is both simple and powerful recognising that in reality business logic does not change and as such was important to separate from the ever changing technologies to “deliver”. Generic but configurable task objects, human and system, and the important links were identified built and displayed in a Graphical Model where build of custom applications takes place with no change to the core code, and no code generation or compiling. Most importantly it removes the interpretation gap between users and “IT” thus removing need for programmers in the build process. There is no need for BPEL BPMN or workflow languages yet addresses all that is required as articulated in the Seven Domains.
David, these claims don’t pass the credibility muster. The reason you find yourself pitching your approach and software everyplace you can find to do so, is because all you are really interested in is selling your software — not getting to the bottom of some fairly sticky problems.
I can offer one technology to bridge all these domains: assembly language programming. It can literally to all of this — in a single, uniform approach. Never mind the fact that it sucks at delivering debugged code, if I go through the “features” mentioned above, I can show that it meets all the requirement.
But that is not the point. These domains represent categories of need, and because of those needs, different categories of technology have been optimized to meet those needs.
Like I have said elsewhere: you can make a vehicle that is both a car and a boat. But it will be a lousy car, and a lousy boat. On the other hand, a boat optimized for bass fishing, will NEVER be a good car, but will beat all car-boat combinations in the things that bass fishermen like to do. Specialization is not necessarily bad. A deep seated desire for a “all-in-one” solution to every problem, does not mean that such a solution exists.
Thus I remind the readers that anyone claiming a “do-all” approach is likely to be just trying to sell you something. As I said in the talk: be very suspicious of any vendor who claims to cover all the bases in a single approach. If their solution really competed well in all categories, then those other categories of software would disappear completely.
Business Process Management itself is an odd beast with three legs. One leg is an approach to managing a business – by using systems business processes as the linkage between strategy to operations, as the framework for how you look for opportunities and challenges. The second leg is about using specialised modeling tools and platforms, principally, to support this ‘management system’. The third leg is about using a broader set of development and analytics tools and platforms to create operational ‘process applications’ that distribute, co-ordinate and monitor work in line with the intent of your management system.
Good what we have done is exactly what you describe “…..getting to the bottom of some fairly sticky problems” something we tackled 15+ years ago! Interestingly one of the key players was ex ICL now Fujitsu who joined us late 90s recognising something they had tried but failed to solve (I believe some £20m later!). I am pleased you recognise it is possible – we just do not need to code so the traditional nightmare you describe does not exist. It is very elegant and because it covers all business logic it intuitively supports those domains using other already proven components; no point reinventing too many wheels!
We did specialise with a single minded approach putting people first where all information is created. Business is simple recognising step by step what needs to be done to achieve goals. We did not even recognise your domains it was almost by accident we discovered the extent of the capability! However we have to try and articulate against the back drop of the complex “mess” IT as created. We do not even see as “doing it all” and frankly not a phrase that crosses our lips! All we just see it is how business works and plug in proven technologies as required.
Of course I want to see this recognised but maybe not for quite on the traditional greed factor that has driven IT for decades. I think customers deserve a better deal from vendors. Domination, as now exist in Enterprise Software, is always bad for progress and the required step change innovation. I need to educate that what is possible has changed. We are not protecting any patent indeed would encourage others to give it go because it does deliver. Of course it might be better to talk to us saving R&D time and money but it will happen and the winner will be the customer. The losers and there are always losers with disruptive technology will be those whose overheads rely on continuing complexity which is what your traditional approach does. You articulate that well “….those other categories of software would disappear completely”.
Just for info US is not on our agenda not interested in “selling” direct. Americans buy from Americans so no point trying so sorry even if someone wanted we would need to do a deal with a favoured supplier; so no quick sale – as I say it is currently about educating – something not to be recommended to try an make money but I have no choice!
Pingback: Adaptive Case Management – HSE Theory and Practice