
Too much of a focus on the on the business process can cause a business solution to be poorly designed and problematic. This is a story from several customers who followed the BPM methodology too well, and were blindsided by some nightmarish systems issues. Too much process can be a real problem.
Process is King
We know that the mantra for BPM is to design everything as a process. The process view of work allows you to assess how well work gets from beginning to end. It allows you to watch and optimize cycle time, which is essential to customer satisfaction.
BPM as a management practice is excellent. However, many people see BPM as a way to design an application. A process is drawn as a diagram, and from this the application is created. This can be OK, but there is a particular pitfall I want to warn you about.
A Sample Process
Consider the following hypothetical process between servers in a distributed environment:
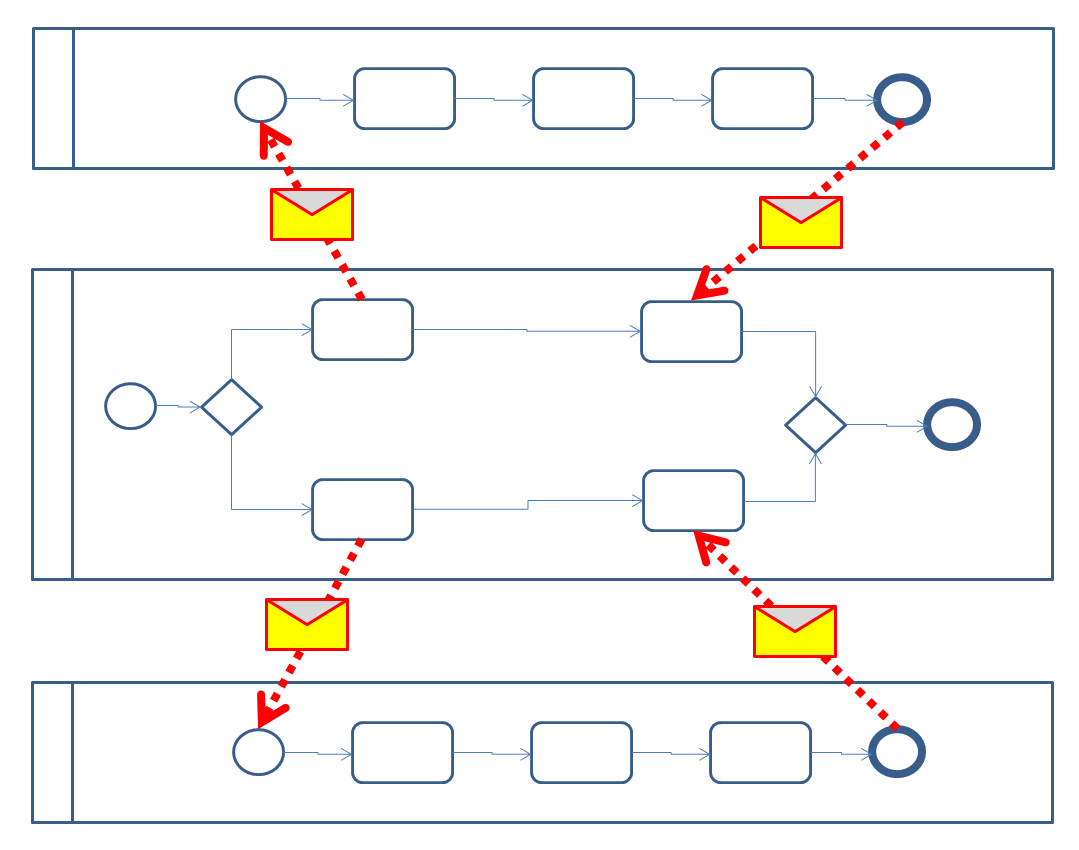 Here we have a process in system B (in the middle) that splits into a couple of parallel branches. Each branch uses a message to communicate to an external remote system (systems A and C) and start a process there. When those processes complete, the messages comes back and eventually the middle process completes. This is a “remote subprocess” scenario.
Here we have a process in system B (in the middle) that splits into a couple of parallel branches. Each branch uses a message to communicate to an external remote system (systems A and C) and start a process there. When those processes complete, the messages comes back and eventually the middle process completes. This is a “remote subprocess” scenario.
What is the matter with this? This seems like a pretty straightforward process. The middle process easily sends a message. Receipt of that message easily start a process. At the end of that process, it easily sends a message back which can easily be received. What could go wrong?
Reliability: Exactly-Once
The assumption being made in this diagram is that the message is delivered exactly once. “Exactly-once” is a term of art that means that the message is delivered with 100% reliability, and a duplicate is never seen by the receiver.
Any failure to deliver a message would be a big problem: Either the sub-proesses would not be started, or the main process would not get the message to continue. The overall process would then be stuck. Completely stuck. The middle process would be inconsistent with the remote processes, and there is no way to ever regain consistency.
So, then, why not just implement the system to have exactly-once message delivery? Push the problem down to the transport level. Build in reliability and checking so that you have exactly once delivery. In a self-contained system, this can be done. To be precise, within a single host, or a tightly bound set of hosts with distributed transactions (two phase commit) it is possible to do this. But this diagram is talking about a distributed system. These hosts are managed independently. The next section reveals the shocking truth.
Exactly-Once Delivery does not Exist
In a distributed system where the machines are not logically tied and managed as a single system, it is not possible to implement — nor do you want to implement — true exactly once reliable message delivery. Twice recently, a friend of mine from Microsoft referenced a particular blog post on this topic: You Cannot Have Exactly-Once Delivery. There is another discussion at: Why Is Exactly-Once Messaging Not Possible In A Distributed Queue?
This is a truism that I have believed for a long time. I never expect reliable message delivery. There is a thought experiment that help one understand why if we could implement exactly-once delivery, you would not want it. Think about back-up, and restoring a server from backup. Systems A, B, and C are managed separately. That means they are backed up separately. Imagine that a disk blows up on system C. That means that a replacement disk will be deployed, and the contents restored from backup, to a state that is a few moments to a few hours ago. Messages that were reliably delivered during that gap, are certainly not delivered, and the system is stuck. The process that had been rolled back will send extra messages, that will in turn cause redundant processes on the remote systems, which might (if the interactions were more elaborate) cause them to get stuck.
Exactly once delivery attempts to keep the state of systems A, B, and C in sync. Everything works in the way that a Rube Goldberg machine works: as long as everything works exactly as expected you can complete the process, but if anything trips up in the middle all is lost. The backup scenario destroys the illusion of distributed consistency. System C is not in sync, and there is no way to ever get into sync again.
So .. All is Lost?
We need reliable business processes, and it turns out that can be done using a consistency seeking approach. What you have to do is to assume that messages are unreliable (as they are). From a business process point of view, you want to visualize the process as a message delivered, but you do not want to architect the application to literally use this as the mechanism of coordination between the systems.
You need a background task that reads the state of the three systems, and attempts to get them into sync. For example, when system B sends a message to system C, it also registers records the fact that it expects system C to run a subprocess. System C, when receiving a message, records the fact that it has a subprocess running for system B. A background task will ask system B for all the subprocesses that it expects to be running on system C, then it asks system C for a list of all the processes it actually is running for system B. If there is a discrepancy, it takes action.
Consider, for example, system B having a process XYZ that is waiting on system C for a subprocess. The consistency seeker asks system C if it has a process for XYZ running. There are two problem scenarios: either there is no such process, in which case it tells system B to re-send the message starting the process. The other possibility is that the process is there, but it has already completed, in which case it tell system C to resend the completion message. So if things are out of sync, a repeat message is prompted. The other requirement is that if, by bad luck, a redundant message is received, it is ignored. Those two things: resending messages and ignoring duplicates are the essential ingredients of implementing reliable processes on top of an unreliable transport — and it works in distributed systems.
Consistency Seeking
Consistency seeking solves the problem at the business process level, and not at the transport level.
It even works if the system is restored from backup. For example, imagine that system B (the middle system) is restored from a backup made yesterday, while systems A and C are left in today’s state. In such a case, there may be processes that had been completed, but are not yet completed in the restored state. The consistency seeking mechanism will check, and will prompt the re-sending of the messages that will eventually bring the systems into a consistent state. It is not perfect—there are situations where you can not automatically return to synchronized state—but it works for most common business scenarios. It certainly works in the case where a simple message was lost. It is far less fragile than the system that assumes that every message is delivered exactly-once.
Conclusion
Process oriented thinking causes us to think about processes in isolation. We forget that real systems need to be backed up, real systems go up and down, real systems are reconfigured independently of each other. The process oriented approach ignores those to focus exclusively on one processes, with the assumption that everything in that process is always perfectly consistent.
This does not mean that you should not design with a process. It remains important for the business to think about how your business is running as a process. But, naïvely implementing the process exactly as designed will result in a system that is not architected for reliability in a distributed environment. BPM is not a replacement for good system architecture.

Hi Keith:
Interesting post about how design principles are loosing its credibility as processes become much more complex and interrelated.
When you have distributed or embedded systems a stateless architecture is more appropriate than focusing in the messaging type. That should be correct approach that allows a distributed system to operate ( by the way there are fault tolerance messaging used in critical information systems that never fail).
But still your point is valid about process design. The challenge is process designers or engineers must evolve deeper in their skills to properly design the next have of advanced processes.
thanks for the comment, Alberto.