
In previous post I introduce a scenario for cooperation between doctors, and show that a personal assistant is a good way to connect those in real time. Here are some additional details that we should consider more carefully.
(Update: this post has had the terms changed to align with: Not an Agent, but a Personal Assistant.)
Not as Easy as it Looks
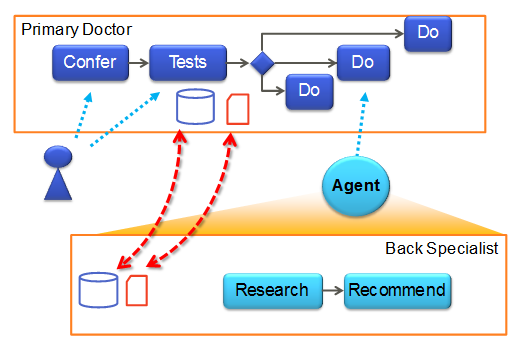
This diagram makes the personal assistant’s job look like it is simply invoking a subprocess. Better, the primary care physician has a process, which calls a process from Charles, the back specialist. However, this is only one case out of many possibilities.
The Fan-Out Problem
I picked one scenario, and gave the players names so we can talk about them, but in reality there are many primary care physicians, and many specialist who might be referred to, for many different specializations. 
This means that Charles, our back specialist in the middle, needs to be prepared to receive referrals from any number of other doctors. Similarly as the scenario continues, he needs to be able to refer the patient to any number of other specialists, the case in point being a physical therapist. Even in this simple scenario in a small community there are thousands of possible routes.
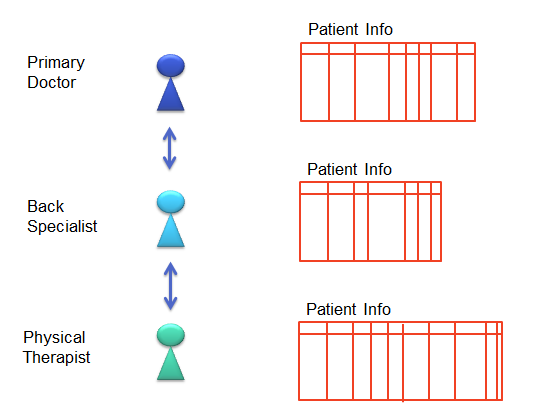
If you know ahead of time that a process will call a particular subprocess, then it is easy to arrange that the processes use the same schema and represent the same information in the same way. What we need to remember is that this is about two different people, designing schema at different times, possible for slightly different purposes, and getting them to work automatically together.
Dying for Standards
Why don’t we get together and come up with some standards that would allow all processes to be hooked together all the time. For example, when a primary care physician refers a patient to a back care specialist, they should always do this in the same way. We might invent then a controlled vocabulary that defines all the possible terms in an unambiguous way, and require everyone to use them properly. This is precisely how the problem is solved in a closed system: in a single development project. It is not possible to use this approach because medical knowledge is always expanding. New treatments, new techniques, new drugs are being invented everyday. It all simply moves too fast to make a single dictionary with all terms well defined.
A data format standard, HL7, is a laudable attempt to make a common structure. In anything to do with medicine this should certainly be used as a framework for storing patient data. But HL7 is not done. The basic framework is there, but the details are not specified for all situations. The group has strategic objectives going out to the year 2020, but we can’t wait until then to design the system. A realistic approach will have to incorporate the idea that these standards are being developed along side treating patients, and the systems will have to muddle along with imperfect information representations.
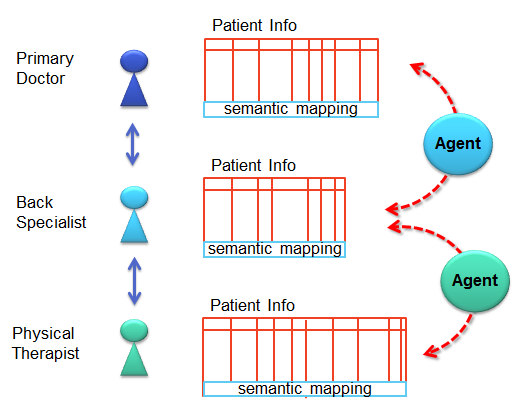
Semantic Mapping
The model that will work is one that is working today by the Securities and Exchange Commission (SEC). Information being passed around in instance document refer to published taxonomies / ontologies. Different parties can publish taxonomies that extend other taxonomies. As long as everyone uses the same basic taxonomy, published by the SEC, then all the documents can be exchanged. At the same time, subdivisions of the market can use their extended taxonomies to transfer more highly specialized information. 15,000 publicly traded companies file their financial reports with the SEC using this method today, and it works.
This becomes a key job for the personal assistant to access these taxonomies/ontologies, and to translate between them. The relationship might look a bit like this:
Synchronizing in Both Directions
Much of this discussion has focused on Task Introduction, those things that must be done when a task if first offered and you are expected to either pick it up or not. The personal assistant also has a role to play while the task is being performed. If the task takes a while, there may be intermediate results. There may be tests that support some conclusions which should be communicated to others to keep everyone coordinated.
A good example is that a doctor may be given the goal of treating a particular problem, and that treatment may take many months. Treating this interaction as you might a subroutine call: information is passed in at the beginning, and all the results come back when the treatment is finished, does not support the real exchange of information that is needed. While treatment is proceeding, the patient may go back to the primary doctor because of a completely different problem. That problem might or might not be a side effect of the treatment. The only way to know this, is for the doctor to be informed about the treatment, and progress.
The general model should not be like a subroutine call. Instead, the general model should be one where both the calling doctor, and the called doctor, exchange information to keep each other in sync while the treatment is proceeding. This is another task that can be taken up by the personal assistant, to regularly push updates back to the caller so they can be informed about progress.
Assistant is Personal
The job of a personal assistant is to really act on your behalf. It does all of these:
- Receiving and screening notification – filter the spam for relevant notifications.
- Task Introduction – find offered tasks, gather additional information about the task to evaluate using a set of rules whether this task is interesting.
- Task Acceptance – sending a notice back to the sender that the offer is interesting and going to be considered by a human.
- Clone Project – based again on rules it may automatically retrieve all the accessible information in the project, and put it safely in a local place for access.
- Determine the Right Template – again based on rules, and start the process if necessary.
- Transform – access the taxonomies that give the semantic meaning of the data, and use that to transform the data to a form that you are used to, and to transform back again when responding.
- Synchronize – in both directions: pull down new documents and information that appear at the original site, and to push back modified information, or new documents, to the originating doctor’s site, in anticipation of the need.
Spelled out this way, personal assistants seem quite a bit less magical than most of the marketing rhetoric builds them up to be. At the same time, this outlines a clear and important mode of use for personal assistants for cooperating knowledge workers.
Comments?

Hi Keith, you present many relevant considerations in this post. I have two observations to add.
First, the relationshio between ontology and taxonomy. Taxonomy is a classification of items into a class or type tree. This can be happening by tagging or feature commonality. But to be usable by an agent the classification has to be quite good and it requries an ontology to describe the tags and/or features and their values. This is where the problem starts with getting to a common ontology as you write. Most generic ontologies are actually quite useless.
The alternative is to use generic pattern matching, which does however require a common source for generating patterns and that is difficult to do across disparate systems. One can create abstract taxonomies from raw data patterns that just point to likeness in type or class, but does not allow automatic linking to an ontology. That prohibits the use of rules derived from taxonomy information.
Second, also to write rules that the agent uses to classify or act otherwise requires an ontology. Once again it is a substantiall issue if agents are rule driven. Some boundary rules are ok, but not general agent function. Systems will be less dynamic and adaptive than BPM flow-diagrams if everything has to be encoded by humans into rules. Just look at the frozen rule structures in BREs and you know what I mean. Any change to tules or their data structures is a drama.
Therefore, the rule-driven agents today are NOT magical at all. They represent a reduction in free flow collaboration that is really the key for better outcomes. The list of agent activities is in my mind not realistic. For any reasonably complex process/case structure the coding necessary to make an agent do these things well and safely is a huge project. Consider that ontology transformation is a really dangerous activity especially if you talk about people’s health information.
I come back to proposing that an agent should learn what to do by observing humans and learn from matching actions to data patterns to recommend ‘Best Next Actions’. Such an agent has to consider the completely unstructured and unique data set of each case. It is virtually impossible to write rules for that. You might have many blood tests done over a longer period and therefore you have duplicate data and when these tests were done in relationship to a treatment is as relevant as the serological values. Sure final judgement must be by a doctor but for the agent to be of any help at all and not just cause more work for the doctor, it has to be able to interpret the data correctly.
Re: Sub-case, sub-tasks or sub-routines — let me point out that also here one cannot disconnect the one from the other. This is not about syncronizing the data by an agent. Yes, each doctor has to know exactly what the other doctors are doing. Many people die because they don’t. But everyone doing all checks on all medications is a huge waste of time. A pattern-matching agent could be trained by an expert to recognize mismatches in medication to physiology/serology and versus other medication. Once again, rules won’t be doing this anytime soon because of the aforementioned reasons. Who will maintain them. But in principle one could build a central agent facility that is called to frequently check patient case records for problem medication patterns and doctors would have to wait until they receive a list of things to check for from the agent.
All in all, the word agent is misused heavily today in marketing as is SMART, or worse Smart-Agent.
The SEC uses the XBRL standard, which involves things called taxonomies which are actually ontologies. That is why I was purposefully blurry about the terms.
To respond to your comment, you see agents contributing by doing forward simulations using case-based logic to provide helpful suggestions on what might be done next. Completely agree that this is good. However, is it really something we should call an “agent”?
XBRL has nothing to do with taxonomies and it does not use or define an ontology. The terminology used in XBRL could be defined in an ontology. You are right that the subject is mostly appled in a blurry way … that actually does not help anyone.
What is an agent supposed to do? There are many definitions and most are conflicting. An agent performs some activity that might be done by a human and the agent acts in lieu of. What would you do to find out what might be best done next? You ask someone who knows. That can be an agent too. But clearly naming is a personal choice.
Pattern matching has nothing to do with forward simulations at all and it does not use logic. It finds patterns in past case data and structures that are related to actions and events and when these patterns reappear at certain events it will suggest those actions based on a probability match. That is in effect how humans gain and use experience. Even if there is no logical reason we do know the right answer (if we aren’t falling for one of the human decision biases … Kahnemann, Gigerenzer et.al.) The agent won’t at least have those to deal with. But as it learns from human actors it might exhibit similar fallacies. 😉
http://xbrl.us/taxonomies/Pages/default.aspx
Pingback: A Scenario for Discussing Personal Assistants | Collaborative Planning & Social Business